大型语言模型 (LLM) 已成为各种自然语言处理 (NLP) 任务不可或缺的工具。传统的 LLM 在令牌级别运行,一次生成一个单词或子单词的输出。然而,人类认知在多个抽象层次上起作用,从而能够进行更深入的分析和创造性推理。
为了解决这一差距,在一篇新论文《大型概念模型:句子表示空间中的语言建模》中,Meta 的一个研究团队引入了大型概念模型 (LCM),这是一种在更高语义级别处理输入的新型架构。这种转变使 LCM 能够实现跨语言的显著零样本泛化,其性能优于同等规模的现有 LLM。

LCM 设计背后的主要动机是在概念层面而不是代币层面实现推理。为了实现这一点,LCM 采用了一种称为 SONAR 的语义嵌入空间。与传统的基于标记的方法不同,这种嵌入空间允许更高阶的概念推理。SONAR 已经在 xsim 等语义相似性指标上表现出强大的性能,并已成功用于大规模双文本挖掘以进行翻译。
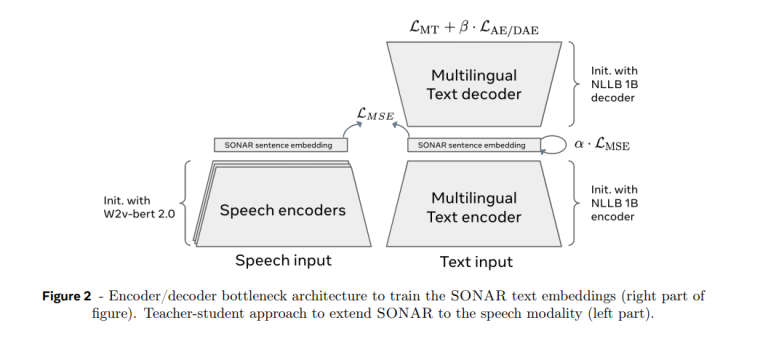
SONAR 是一种编码器-解码器架构,其特点是用固定大小的瓶颈层代替交叉注意力。SONAR 的训练目标结合了三个关键组成部分:
- 机器翻译目标:在 200 种语言和英语之间进行翻译。
- 降噪自动编码:从损坏的版本中恢复原始文本。
- 均方误差 (MSE) 损失:在嵌入瓶颈上添加显式约束,以提高语义一致性。
通过利用这个嵌入空间,LCM 获得了处理概念而不是标记的能力。这使模型能够在 SONAR 支持的所有语言和模态中执行推理,包括传统 LLM 通常服务不足的低资源语言。
为了在概念层面生成语言,LCM 的设计遵循一个多步骤的过程:
- 分割:输入文本被划分为多个句子。
- 概念编码:使用 SONAR 编码器将每个句子转换为一系列概念嵌入。
- 概念推理:LCM 处理这个概念嵌入序列以生成新的概念序列。
- 解码:SONAR 将输出概念解码回子词或标记。
这种架构允许 LCM 维护一个更抽象、与语言无关的推理过程,从而可以更好地跨语言和模态进行泛化。
大型概念模型引入了几项关键创新,使其有别于传统的 LLM:
- 跨语言和模态的抽象推理:LCM 的概念方法使其能够超越任何特定语言或模态的限制进行推理。这种抽象有助于多语言和多模式支持,而无需重新训练。
- 显式层次结构:通过使用概念而不是标记,LCM 的输出更容易被人类解释。这还使用户能够进行本地编辑,从而改善人机 AI 协作。
- 更长的上下文处理:由于 LCM 在概念级别运行,因此其序列长度明显短于基于令牌的转换器,从而能够有效地处理更长的上下文。
- 无与伦比的零镜头泛化:无论 LCM 在哪种语言或模态上训练,它都可以应用于 SONAR 编码器支持的任何语言或模态。这允许零样本泛化,无需额外的数据或微调。
- 模块化和可扩展性:LCM 的设计允许独立开发概念编码器和解码器,避免了多模态 LLM 中的“模态竞争”。新的语言或模式可以无缝地添加到现有系统中。

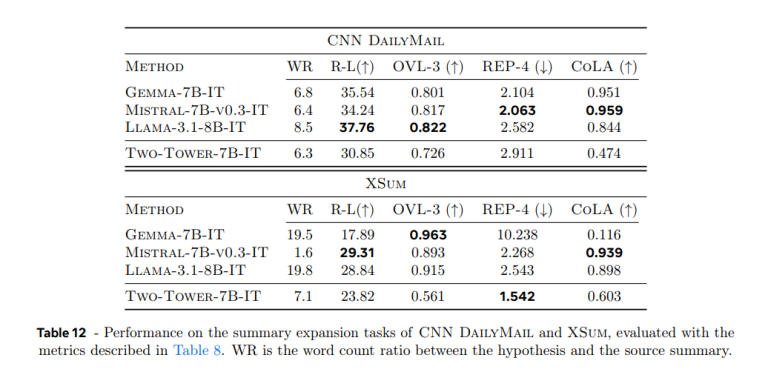
Meta 的研究团队测试了 LCM 在生成式 NLP 任务上的性能,包括摘要和摘要扩展的新任务。结果表明,LCM 在各种语言中实现了卓越的零样本泛化,明显优于相同大小的 LLM。这展示了 LCM 在各种语言和上下文中生成高质量、人类可读输出的能力。
总之,Meta 的大型概念模型 (LCM) 代表了从基于标记的语言模型到概念驱动推理的开创性转变。通过利用 SONAR 嵌入空间和概念推理,LCM 实现了卓越的零镜头泛化,支持多种语言和模态,并保持模块化、可扩展的设计。这种新方法有可能重新定义语言模型的功能,为更具可扩展性、可解释性和包容性的 AI 系统打开大门。
该代码可在项目的 GitHub 上找到。论文 Large Concept Models: Language Modeling in a Sentence Representation Space 位于 arXiv 上。



发表评论 取消回复