大型语言模型 (LLM) 的最新进展主要集中在增强它们以向前、时间线性方式预测文本的能力。然而,新兴研究表明,使 LLM 能够回顾性地批评和完善自己的成果可以显着提高他们的表现。虽然有效,但现有方法依赖于大容量 LLM 固有的高级推理和指令跟踪能力。此外,这些方法通常涉及对生成的响应进行顺序处理,从而导致推理时间大幅增加。
在一篇新论文《时间反转为 LLM 提供无监督反馈》中,来自 Google DeepMind 和印度科学研究所的研究团队提出了时间反转语言模型 (TRLM),这是一个允许 LLM 反向推理的框架——以与传统正向方法相反的方式评分和生成内容。与根据查询预测响应的传统 LLM 不同,TRLM 根据响应预测或评估查询,从而促进推理过程中的无监督反馈。

研究人员提出了 TRLM 的两种关键变体。第一个称为 TRLM-Fo(“基于前向”),将现有的前向训练的 LLM 重新用于以反向方式运行。这是通过使用诸如 “Generate a question that would result in the following answer:” 之类的提示来指导模型的行为来实现的。第二种变体 TRLM-Ba(“向后”)采用更基本的方法,即从头开始以令牌反转的方向预训练 LLM。这些模型不是在传统的正向学习,而是学习反向预测标记,从而为向后推理提供更自然的能力。
该研究结果表明,TRLM 提供有意义的无监督反馈,可以提高预训练、微调和指令调整模型的性能。TRLM 的应用涵盖各种下游任务,包括对开放式长篇问答的响应进行重新排序、引文生成和信息检索。至关重要的是,研究人员证明 TRLM 的反向评分功能(模型根据响应对查询进行评分)有助于实现这些收益。此外,使用 TRLM-Ba 方法训练的模型通常优于 TRLM-Fo 模型,这凸显了原生向后预训练的价值。
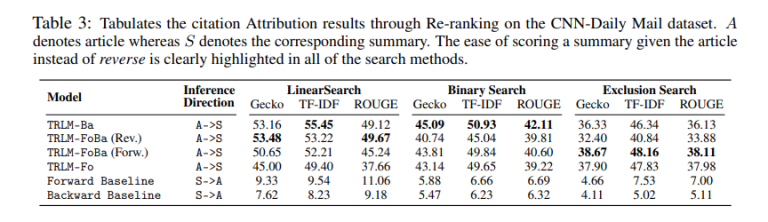
实证结果突出了 TRLM 在实际应用中的有效性。在广泛使用的 AlpacaEval 排行榜上,TRLM 比依赖自对数困惑分数进行 N 局两胜制重新排名的强大基线提高了 5%。值得注意的是,TRLM 在引文生成和段落检索等关键任务中优于传统的正向评分(查询→响应)方法。
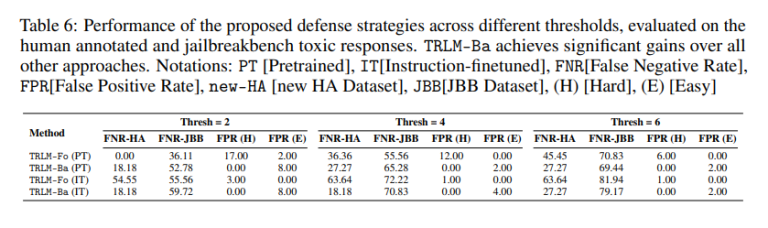
除了重新排序和检索之外,研究人员还利用 TRLM 的生成能力来增强 LLM 的输入安全过滤器。通过从已知响应生成潜在查询,TRLM 有助于更有效地识别不安全的输入。这种方法大大降低了 JailbreakBench 排行榜上的假阴性率,该排行榜是评估 LLM 安全性的基准。重要的是,这种改进是在没有显着增加假阳性率的情况下实现的,展示了该方法对对抗性输入的稳健性。
总之,时间反转语言模型 (TRLM) 为 LLM 生成、排名和评估内容的方式提供了范式转变。通过启用反向推理和评分,TRLM 引入了一种新颖的无监督反馈形式,可以提高现有模型和新训练模型的性能。它们在重新排序、检索和安全筛选方面的有效性使它们成为 LLM 工具包的有前途的补充,为更快、更高效的语言模型部署铺平了道路。



发表评论 取消回复