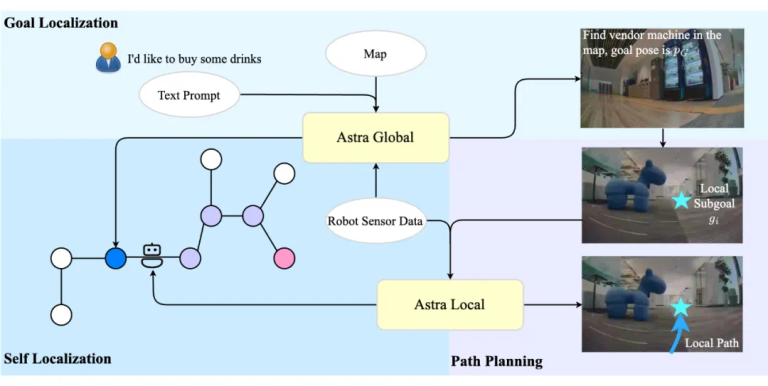
从工业制造到日常生活,机器人在各个领域的集成程度不断提高,这凸显了对高级导航系统日益增长的需求。然而,现代机器人导航系统在多样化和复杂的室内环境中面临着重大挑战,暴露了传统方法的局限性。为了解决“我在哪里”、“我要去哪里”和“我如何到达那里”等基本问题,字节跳动开发了 Astra,这是一种创新的双模型架构,旨在克服这些传统导航瓶颈并支持通用移动机器人。
传统的导航系统通常由多个较小的模块组成,这些模块通常基于规则,用于处理目标定位、自定位和路径规划等核心挑战。目标定位涉及理解自然语言或图像线索以在地图上精确定位目的地。自我定位需要机器人来确定其在地图上的精确位置,这在仓库等重复环境中尤其具有挑战性,因为传统方法通常依赖于人工地标(例如 QR 码)。路径规划进一步分为用于生成粗略路线的全局规划以及用于实时避障和到达中间航点的本地规划。
虽然基础模型在集成较小的模型以处理更广泛的任务方面显示出前景,但模型的最佳数量及其用于全面导航的有效集成仍然是一个悬而未决的问题。

字节跳动的 Astra 在其论文“Astra:通过分层多模态学习迈向通用移动机器人”(网站:https://astra-mobility.github.io/)中详细介绍了这些限制。遵循 System 1/System 2 范式, Astra 具有两个主要子模型: Astra-Global 和 Astra-Local。Astra-Global 处理目标和自定位等低频任务,而 Astra-Local 管理本地路径规划和里程计估计等高频任务。这种架构有望彻底改变机器人在复杂室内空间中导航的方式。
Astra-Global:全球本地化的智能大脑
Astra-Global 作为 Astra 架构的智能核心,负责关键的低频任务:自定位和目标定位。它充当多模态大型语言模型 (MLLM),擅长处理视觉和语言输入,以实现地图内的精确全球定位。它的优势在于利用混合拓扑语义图作为上下文输入,使模型能够根据查询图像或文本提示准确定位位置。
这个强大的本地化系统的构建从离线地图绘制开始。研究团队开发了一种离线方法来构建混合拓扑语义图 G=(V,E,L):
- V(节点):通过对输入视频和 SfM 估计的 6 自由度 (DoF) 摄像机姿势进行时间下采样获得的关键帧充当编码摄像机姿势和地标参考的节点。
- E(边):无向边根据相对节点姿势建立连通性,这对于全局路径规划至关重要。
- L (地标):Astra-Global 从每个节点的视觉数据中提取语义地标信息,丰富了地图的语义理解。这些地标存储语义属性,并通过共视关系连接到多个节点。
在实际本地化中,Astra-Global 的自我定位和目标本地化功能利用从粗到细的两阶段流程进行视觉语言本地化。粗略阶段分析输入图像和定位提示,检测地标,与预先构建的地标地图建立对应关系,并根据视觉一致性筛选候选对象。然后,fine 阶段使用查询图像和粗略输出从离线地图中对参考地图节点进行采样,比较它们的视觉和位置信息,以直接输出预测的姿势。
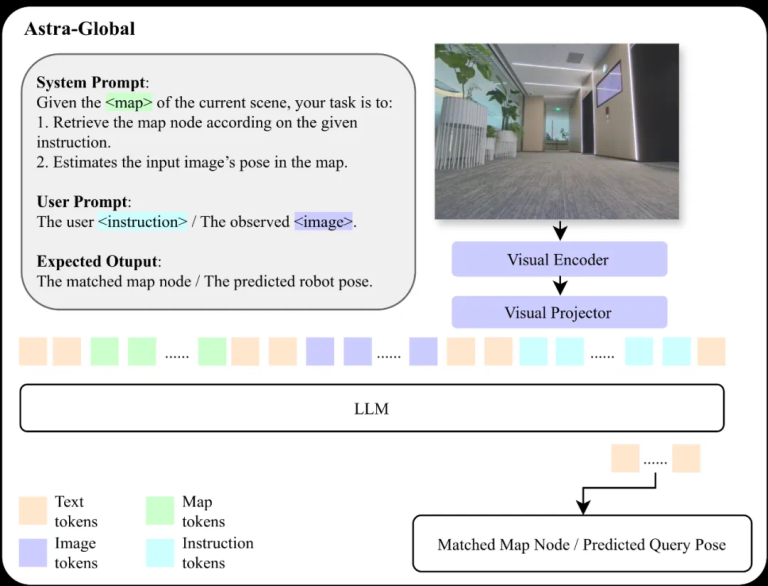
对于基于语言的目标定位,该模型会解释自然语言指令,使用地图中的功能描述识别相关地标,然后利用地标到节点的关联机制来定位相关节点,检索目标图像和 6-DoF 姿势。
为了赋予 Astra-Global 强大的本地化能力,该团队采用了细致的培训方法。他们以 Qwen2.5-VL 为主干,将监督微调 (SFT) 与组相对策略优化 (GRPO) 相结合。SFT 涉及用于各种任务的不同数据集,包括粗略和精细定位、协同可见性检测和运动趋势估计。在 GRPO 阶段,使用基于规则的奖励函数(包括格式、地标提取、地图匹配和额外的地标奖励)来训练视觉语言定位。实验表明,GRPO 显著提高了 Astra-Global 的零样本泛化,在看不见的家庭环境中实现了 99.9% 的定位准确率,超过了仅 SFT 的方法。
Astra-Local:本地规划的智能助手
Astra-Local 充当 Astra 高频任务的智能助手,这是一个多任务网络,能够高效生成本地路径并根据传感器数据准确估计里程计。其架构由三个核心组件组成:4D 时空编码器、规划头和里程计头。
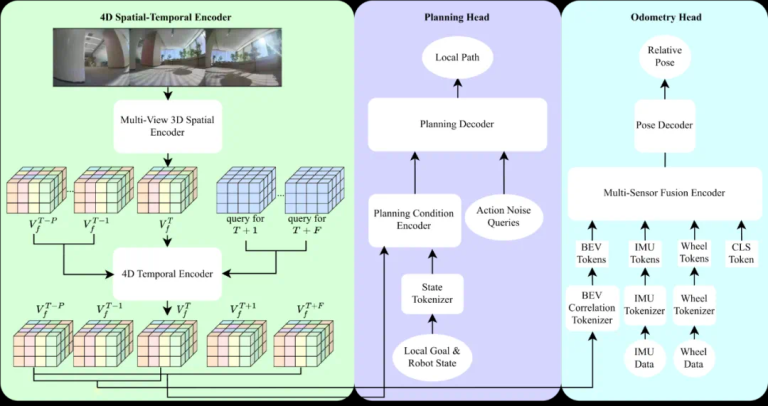
4D 时空编码器取代了传统的移动堆栈感知和预测模块。它从一个 3D 空间编码器开始,该编码器通过 Vision Transformer (ViT) 和 Lift-Splat-Shoot 处理 N 个全向图像,以将 2D 图像特征转换为 3D 体素特征。该 3D 编码器通过 3D 体积可微分神经渲染使用自我监督学习进行训练。然后,4D 时空编码器基于 3D 编码器构建,将过去的体素特征和未来的时间戳作为输入,通过 ResNet 和 DiT 模块预测未来的体素特征,为规划和里程计提供当前和未来的环境表示。
规划头基于预先训练的 4D 特征、机器人速度和任务信息,使用基于 Transformer 的流程匹配生成可执行轨迹。为了防止碰撞,规划头合并了一个掩蔽的 ESDF 损失(欧几里得有符号距离场)。此损失会计算 3D 占用地图的 ESDF 并应用 2D 地面实况轨迹掩码,从而显著降低碰撞率。实验表明,与其他方法相比,它在分布外 (OOD) 数据集上的碰撞率和总分方面具有优异的性能。
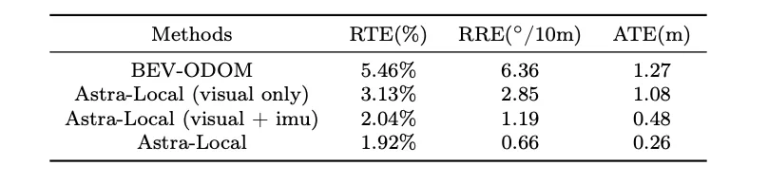
里程计头使用当前和过去的 4D 特征以及其他传感器数据(例如 IMU、车轮数据)预测机器人的相对姿态。它训练 Transformer 模型来融合来自不同传感器的信息。每个传感器模态都由特定的分词器处理,结合模态嵌入和时间位置嵌入,馈送到 Transformer 编码器中,最后使用 CLS 分词来预测相对姿势。实验表明,里程计头在多传感器融合和姿态估计方面表现出色,显著提高了旋转精度并降低了整体轨迹误差。
实验验证
在不同的室内环境(仓库、办公室、家庭)中进行了广泛的实验,以全面评估 Astra 的性能。
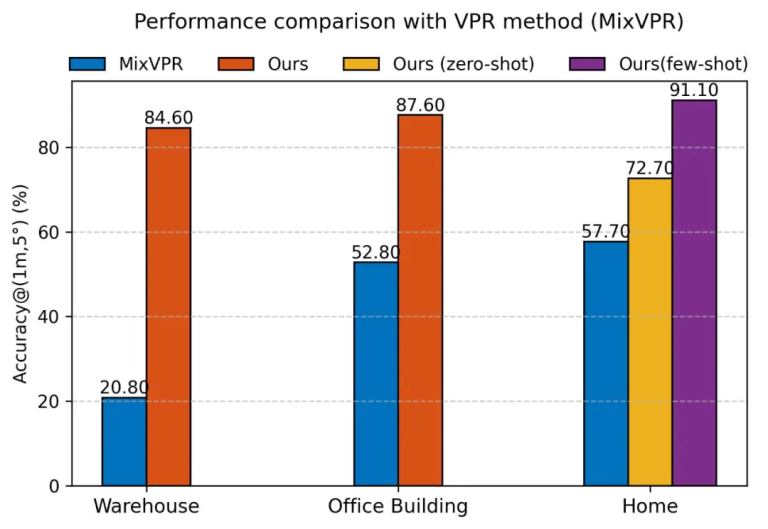
Astra-Global 的多模式定位功能通过各种实验进行了验证,在处理文本和图像定位查询方面表现出卓越的性能。对于目标定位,它根据文本命令(例如,“查找休息区”)准确识别匹配的图像和姿势。与传统的视觉位置识别 (VPR) 方法相比,Astra-Global 在以下方面表现出显著优势:
- 细节捕捉:与 VPR 对全局功能的依赖不同,Astra-Global 可以精确捕捉房间号等精细细节,从而防止类似场景中出现定位错误。
- 视点稳健性:基于语义地标,Astra-Global 即使在摄像机角度变化较大的情况下也能保持稳定的定位,而 VPR 方法通常会失败。
- 姿势精度:Astra-Global 利用地标空间关系来选择最佳匹配姿态,与传统 VPR 相比,姿态精度(1 米距离误差和 5 度角度误差以内)明显更高,在仓库环境中性能提高了 30% 以上。
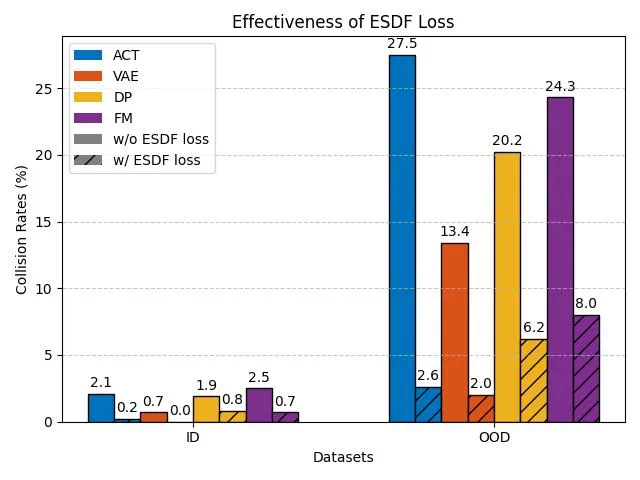
Astra-Local 的规划和里程计头经过了全面评估。使用基于 Transformer 的流匹配和掩蔽 ESDF 损失的规划头在 OOD 数据集上的碰撞率、速度和总分方面优于 ACT 和扩散策略等方法。这突出了掩蔽 ESDF 损失在降低碰撞风险方面的有效性。
里程计头的性能是在多模态数据集上评估的,包括同步图像序列、IMU、车轮数据和地面实况姿态。与两帧 BEV-ODOM 基线相比,Astra-Local 的里程计头在多传感器融合和姿态估计方面表现出显著优势。集成 IMU 数据显著提高了旋转估计精度,将整体轨迹误差降低到约 2%。进一步纳入车轮数据增强了秤的稳定性和估计精度,验证了其卓越的多传感器数据融合能力。
Astra 对未来的开发和应用具有重大前景。它的部署可以扩展到更复杂的室内环境,如大型购物中心、医院和图书馆,在那里它可以协助完成精确的产品位置、高效的医疗用品交付和书籍组织等任务。
但是,仍存在需要改进的地方。对于 Astra-Global,虽然当前的 map 表示平衡了信息丢失和标记长度,但它们有时可能缺乏关键的语义细节。未来的工作将侧重于替代映射压缩方法,以优化效率,同时最大限度地提高语义信息保留率。此外,当前的单帧定位在功能稀缺或高度重复的环境中可能会失败;未来的计划包括主动探索机制和时间推理,以实现更稳健的定位。
对于 Astra-Local,提高对分布外 (OOD) 场景的稳健性至关重要,需要增强的模型架构和训练方法。还计划重新设计 fallback 系统以实现更紧密的集成和无缝切换,以提高系统稳定性。此外,集成指令跟踪功能将使机器人能够理解和执行自然语言命令,扩展它们在动态、以人为本的环境中的可用性,并促进更自然的人机交互。


发表评论 取消回复