Share My Research 是 Synced 的专栏,欢迎学者与超过 2M 的全球 AI 爱好者分享自己的研究突破。除了技术进步之外,Share My Research 还呼吁研究背后的有趣故事和令人兴奋的研究理念。
认识作者
机构:宾夕法尼亚州立大学、杜克大学、Google DeepMind、华盛顿大学、Meta、南洋理工大学和俄勒冈州立大学。共同第一作者是宾夕法尼亚州立大学的 Shaokun Zhang 和杜克大学的 Ming Yin。
近年来,LLM Multi-Agent 系统因其解决复杂问题的协作方法而受到广泛关注。但是,尽管有一系列活动,但这些系统在任务中失败是很常见的。这给开发人员留下了一个关键问题:哪个代理在什么时间点对失败负责?筛选大量的交互日志以查明根本原因感觉就像大海捞针一样,这是一项耗时且劳动密集型的工作。
这是开发人员熟悉的挫败感。在日益复杂的多代理系统中,由于代理协作的自主性和长信息链,故障不仅很常见,而且非常难以诊断。如果无法快速识别故障源,系统迭代和优化就会陷入停顿。
为了应对这一挑战,宾夕法尼亚州立大学和杜克大学的研究人员与包括 Google DeepMind 在内的机构合作,引入了“自动故障归因”这一新颖的研究问题。他们为这项任务构建了第一个基准数据集 Who&When,并开发和评估了几种自动归因方法。这项工作不仅突出了任务的复杂性,还为提高 LLM Multi-Agent 系统的可靠性铺平了一条新道路。
该论文已被顶级机器学习会议 ICML 2025 接受为 Spotlight 演示文稿,代码和数据集现在是完全开源的。

研究背景与挑战
LLM 驱动的 Multi-Agent 系统在许多领域都显示出巨大的潜力。然而,这些系统很脆弱;单个代理的错误、代理之间的误解或信息传输中的错误都可能导致整个任务的失败。

目前,当系统出现故障时,开发人员往往只能使用手动且效率低下的调试方法:
手动日志考古学 :开发人员必须手动查看冗长的交互日志才能找到问题的根源。
依赖专业知识 : 调试过程高度依赖于开发人员对系统和手头任务的深刻理解。
这种 “大海捞针” 的调试方式不仅效率低下,而且严重阻碍了系统快速迭代和系统可靠性的提高。迫切需要一种自动化、系统化的方法来确定故障原因,从而有效地弥合“评估结果”和“系统改进”之间的差距。
核心贡献
本文为解决上述挑战做出了几项开创性的贡献:
1. 定义新问题:该论文是第一篇将“自动故障归因”正式确定为特定研究任务的论文。此任务是通过标识
2. 负责失败的代理和导致任务失败的决定性错误步骤。
构建第一个基准数据集:谁&何时:该数据集包括从 127 个 LLM 多代理系统收集的大量故障日志,这些日志要么是通过算法生成的,要么是由专家手工制作的,以确保真实性和多样性。每个故障日志都附有精细的人工注释,用于:
谁:负责故障的代理。
时间:发生决定性错误的特定交互步骤。
原因:失败原因的自然语言说明。
3. 探索初始的“自动归因”方法:使用 Who&When 数据集,本文设计并评估了三种不同的自动失败归因方法:
All-at-Once:该方法为 LLM 提供用户查询和完整的失败日志,要求它一次性识别责任代理和决定性错误步骤。虽然成本效益高,但在长期上下文中可能难以精确定位错误。
循序渐进:这种方法通过让 LLM 按顺序查看交互日志来模拟手动调试,在每个步骤中做出判断,直到发现错误。它在定位错误步骤方面更精确,但会产生更高的成本,并且有累积错误的风险。
Binary Search:前两种方法之间的折衷方案,这种策略将日志反复分成两半,使用 LLM 来确定哪个段包含错误。然后,它会递归搜索已识别的区段,从而在成本和性能之间取得平衡。
实验结果和主要发现
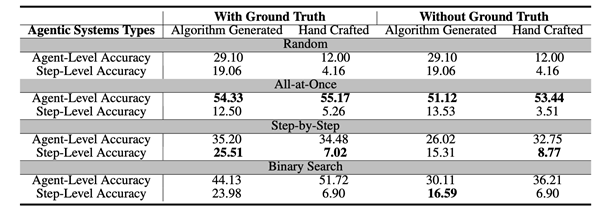
实验在两种设置中进行:一种是 LLM 知道多智能体系统试图解决的问题的 Ground Truth 答案(使用 Ground Truth),另一种是 LLM 不知道 (Without Ground Truth)。使用的主要模型是 GPT-4o,尽管其他模型也进行了测试。在 Who&When 数据集上对这些方法的系统评估产生了几个重要的见解:
- 任重道远:目前的方法远非完美。即使是性能最好的单一方法,在识别负责代理方面也只能达到约 53.5% 的准确率,在精确定位确切错误步骤方面的准确率仅为 14.2%。有些方法的表现甚至比随机猜测还要差,这凸显了任务的难度。
- 没有“多合一”解决方案:不同的方法在问题的不同方面表现出色。All-at-Once 方法更擅长识别 “Who”,而 Step-by-Step 方法在确定 “When” 方面更有效。Binary Search 方法提供了一种中间地带的性能。
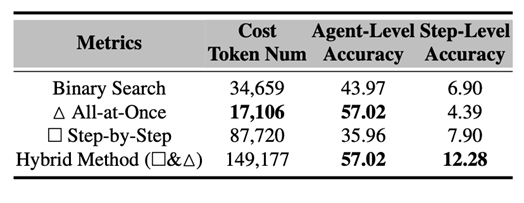
- 混合方法前景光明,但成本高昂:研究人员发现,结合不同的方法,例如使用 All-at-Once 方法识别潜在代理,然后应用 Step-by-Step 方法查找错误,可以提高整体性能。但是,这会显著增加计算成本。
- 最先进的模型难以应对:令人惊讶的是,即使是最先进的推理模型,如 OpenAI o1 和 DeepSeek R1,也发现这项任务具有挑战性。这凸显了自动故障归因的固有难度,它需要比更传统任务所需的更高级别的推理。
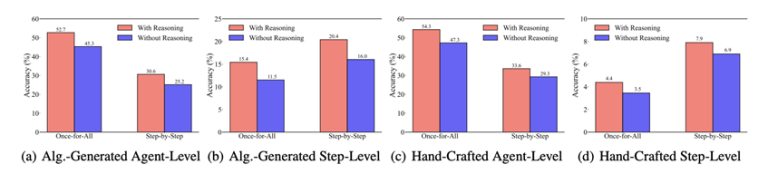
- 显式推理的重要性:提供显式提示,要求 LLM 以 All-at-Once 和 Step-by-Step 方法解释其推理,已被证明可以提高性能。
- 上下文长度是一个限制因素:该研究还显示,随着失败日志的上下文长度增加,所有归因方法的性能都有下降的趋势,对识别错误步骤的准确性影响更为明显。

论文:https://www.willenyao.com/file/202506201157.pdf
代码:https://github.com/mingyin1/Agents_Failure_Attribution
数据集:https://huggingface.co/datasets/Kevin355/Who_and_When



发表评论 取消回复