视频世界模型以动作为条件预测未来帧,为人工智能带来了巨大的前景,使代理能够在动态环境中进行规划和推理。最近的进展,尤其是视频扩散模型,在生成逼真的未来序列方面显示出令人印象深刻的能力。然而,仍然存在一个重大瓶颈:保持长期记忆。由于使用传统注意力层处理扩展序列相关的高计算成本,当前的模型难以记住过去的事件和状态。这限制了他们执行需要持续了解场景的复杂任务的能力。
来自斯坦福大学、普林斯顿大学和 Adobe Research 的研究人员发表了一篇新论文“Long-Context State-Space Video World Models”,提出了一种应对这一挑战的创新解决方案。他们引入了一种新颖的架构,利用状态空间模型 (SSM) 来扩展时态内存,而不会牺牲计算效率。
核心问题在于注意力机制相对于序列长度的二次计算复杂性。随着视频上下文的增长,注意力层所需的资源呈爆炸式增长,这使得长期记忆对于实际应用程序不切实际。这意味着,在一定数量的帧之后,该模型实际上 “忘记” 了以前的事件,从而阻碍了它在需要长时间保持长距离连贯或推理的任务上的性能。
作者的主要见解是利用状态空间模型 (SSM) 的固有优势进行因果序列建模。与以前为非因果视觉任务改造 SSM 的尝试不同,这项工作充分利用了它们在有效处理序列方面的优势。
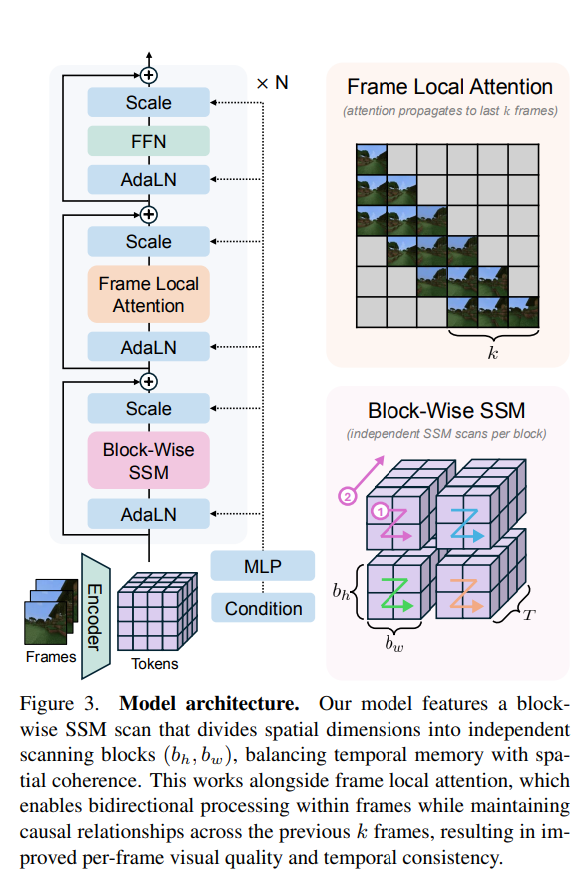
所提出的长上下文状态空间视频世界模型 (LSSVWM) 包含几个关键的设计选择:
- 分块 SSM 扫描方案:这是他们设计的核心。他们不是用一次 SSM 扫描来处理整个视频序列,而是采用逐块方案。这在战略上权衡了一些空间一致性(在一个块内)以换取显著扩展的时态内存。通过将长序列分解为可管理的块,他们可以保持一个压缩的 “状态”,跨块传输信息,从而有效地扩展模型的内存范围。
- 密集的本地关注:为了补偿分块 SSM 扫描引入的空间连贯性的潜在损失,该模型结合了密集的局部注意力。这可确保块内和块之间的连续帧保持牢固的关系,从而保留生成逼真视频所需的精细细节和一致性。这种全局 (SSM) 和局部 (注意力) 处理的双重方法使它们能够同时实现长期记忆和局部保真度。
本文还介绍了进一步提高长上下文性能的两种关键训练策略:
- 扩散强迫:这种技术鼓励模型生成以输入前缀为条件的帧,从而有效地迫使它学习在更长的时间内保持一致性。通过有时不对前缀进行采样并保持所有标记的噪声,训练变得等同于扩散强制,这被强调为前缀长度为零的长上下文训练的特殊情况。这促使模型生成连贯的序列,即使从最小的初始上下文中也是如此。
- 框架本地关注:为了更快地训练和采样,作者实现了 “frame local attention” 机制。与完全因果掩码相比,它利用 FlexAttention 实现了显著的加速。通过将帧分组为多个数据块(例如,帧窗口大小为 10 的 5 个数据块),数据块中的帧在保持双向性的同时,也会关注前一个数据块中的帧。这允许一个有效的感受野,同时优化计算负载。

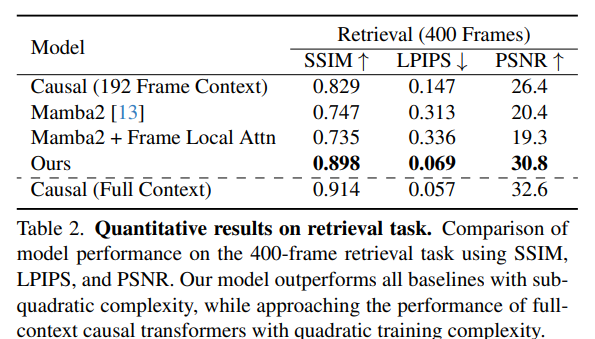
研究人员在具有挑战性的数据集上评估了他们的 LSSVWM,包括 Memory Maze 和 Minecraft,这些数据集是专门为通过空间检索和推理任务测试长期记忆能力而设计的。
实验表明,他们的方法在保留远程记忆方面大大超过了基线。定性结果,如补充图(例如,S1、S2、S3)所示,表明与仅依赖因果注意力甚至没有框架局部注意力的 Mamba2 的模型相比,LSSVWM 可以在较长时间内生成更连贯和准确的序列。例如,在迷宫数据集的推理任务中,他们的模型在长期范围内保持了更好的一致性和准确性。同样,对于检索任务,LSSVWM 显示出更好的回忆和利用遥远过去帧信息的能力。至关重要的是,这些改进是在保持实际推理速度的同时实现的,使模型适用于交互式应用程序。



发表评论 取消回复