假设现有一张人员表(表名:ta_name),若想将姓名(name)这字段完全相同的记录查找出来应该怎么做呢?
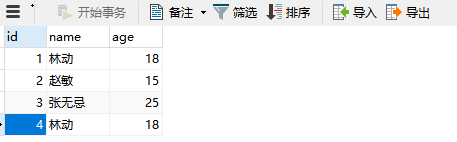
1、查找表中多余的重复记录,根据字段(name)来判断重复数据。
select * from ta_name where name in (select name from ta_name group by name having count(name) > 1)
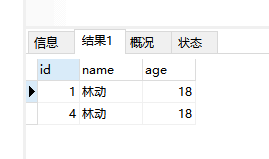
2、删除表中多余的重复记录,重复记录是根据单个字段(name)来判断,只留有id最小的记录,这个亲测有效,网上有一些方法在mysql 5.7版本后就会报1005错。
因为在mysql5.7 sql_mode中默认存在ONLY_FULL_GROUP_BY,SQL语句未通过ONLY_FULL_GROUP_BY语义检查所以报错。我这个sql在任何版本都有效。
DELETE FROM ta_name WHERE id IN (
SELECT id FROM (
select id from ta_name
where name in (select name from ta_name group by name having count(name) > 1)
and id not in (select min(id) from ta_name group by name having count(name)>1)
) t
)
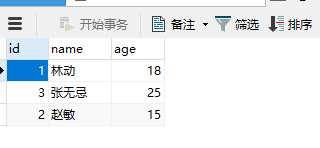
3.补充一条:查询存在一个表而不在另一个表中的数据记录
select A.id from A where A.id not in (select p_id from B WHERE p_id != '')



@alan 当然可以在前期架构规划的时候避免出现这种情况;我这只是个例子,告诉如果想这样操作的一个sql思路。
当初建表时应当属性 唯一啊 老哥我是个新手 别喷我