出处:https://vercel.com/blog/the-rise-of-the-ai-crawler
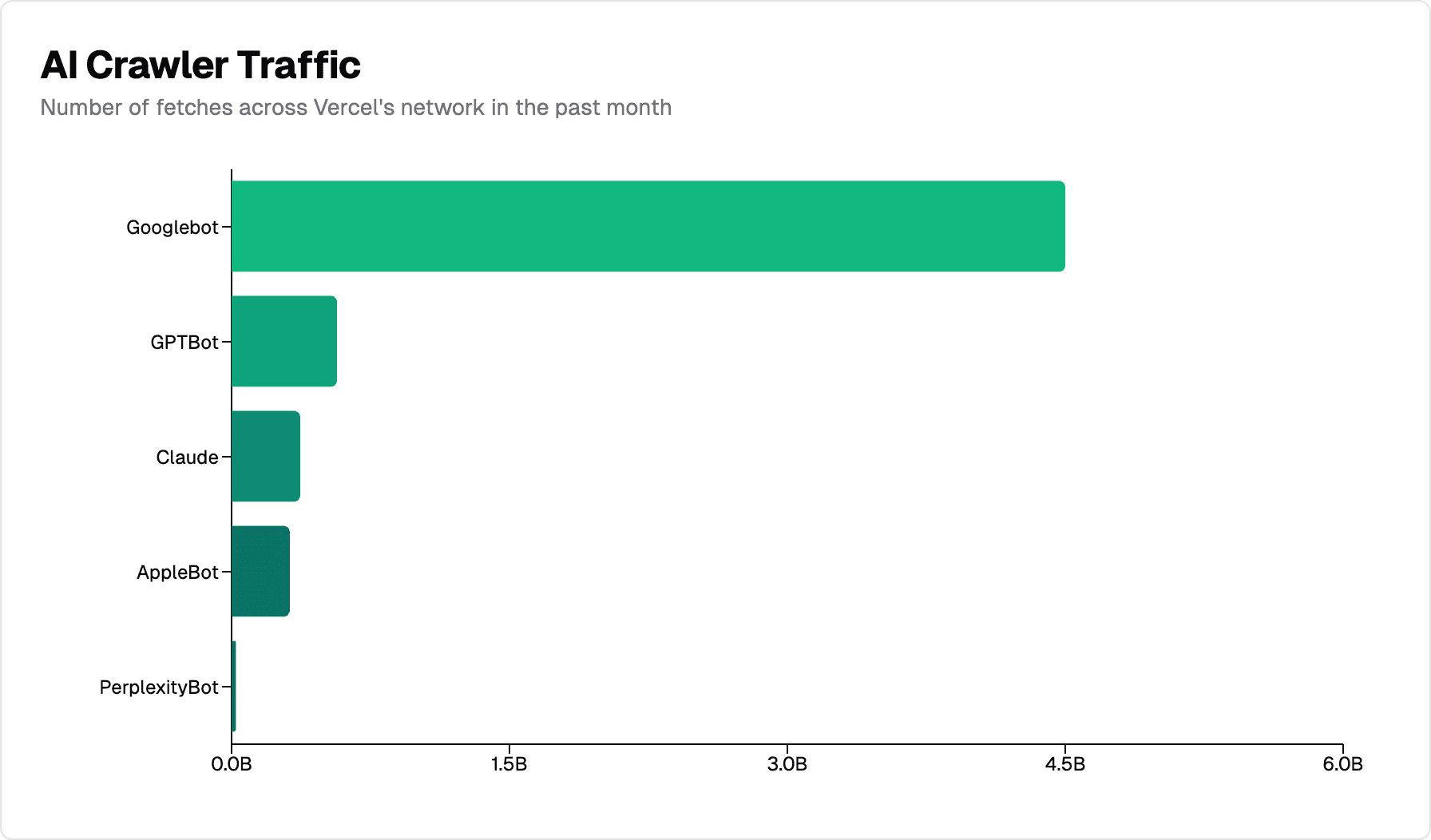
AI 爬虫已成为 Web 上的重要存在。OpenAI 的 GPTBot 在过去一个月在 Vercel 的网络中产生了 5.69 亿个请求,而 Anthropic 的 Claude 紧随其后,产生了 3.7 亿个请求。从长远来看,这一总量约占同期 Googlebot 45 亿次请求的 20%。
在分析了 Googlebot 如何使用 MERJ 处理 JavaScript 渲染后,我们将注意力转向了这些 AI 助手。我们的新数据揭示了 Open AI 的 ChatGPT、Anthropic 的 Claude 和其他 AI 工具如何抓取和处理 Web 内容。
我们发现了这些爬虫如何处理 JavaScript、确定内容类型的优先级和导航 Web 的明显模式,这些模式直接影响 AI 工具理解现代 Web 应用程序并与之交互的方式。
数据收集过程
我们的主要数据来自过去几个月的监控和 Vercel 网络。为了验证我们在不同技术堆栈中的发现,我们还分析了两个求职板网站:使用 Next.js 构建的 Resume Library 和使用自定义整体框架的 CV Library。这个多样化的数据集有助于确保我们对爬虫行为的观察在不同的 Web 架构中保持一致。nextjs.org
注意:Microsoft Copilot 被排除在本研究之外,因为它缺乏用于跟踪的唯一用户代理。
规模和分布
Vercel 网络中的 AI 爬虫流量很大。过去一个月:
-
Googlebot:Gemini 和 Google 搜索的抓取次数达到 45 亿次
-
GPTBot (ChatGPT):5.69 亿次获取
-
Claude:3.7 亿次获取
-
AppleBot:3.14 亿次获取
-
PerplexityBot:2440 万次抓取
虽然 AI 爬虫尚未达到 Googlebot 的规模,但它们代表了网络爬虫流量的很大一部分。就上下文而言,GPTBot、Claude、AppleBot 和 PerplexityBot 总共完成了近 13 亿次抓取,略高于 Googlebot 流量的 28%。
地理分布
我们测量的所有 AI 爬虫都在美国数据中心运行:
-
ChatGPT:得梅因(爱荷华州)、凤凰城(亚利桑那州)
-
Claude:哥伦布(俄亥俄州)
相比之下,传统搜索引擎通常会在多个区域之间分配爬网。例如,Googlebot 在美国的 7 个不同地点开展业务,包括 The Dalles(俄勒冈州)、Council Bluffs(爱荷华州)和 Moncks Corner(南卡罗来纳州)。
JavaScript 渲染功能
我们的分析表明,AI 爬虫之间的 JavaScript 渲染能力存在明显差异。为了验证我们的发现,我们分析了使用不同技术堆栈的 Next.js 应用程序和传统 Web 应用程序。
结果一致显示,目前没有一个主要的 AI 爬网程序呈现 JavaScript。这包括:
-
OpenAI(OAI-SearchBot、ChatGPT-User、GPTBot)
-
Anthropic (ClaudeBot)
-
Meta(Meta-ExternalAgent)
-
ByteDance (Bytespider)
-
Perplexity (PerplexityBot)
结果还显示:
-
Google 的 Gemini 利用 Googlebot 的基础架构,实现了完整的 JavaScript 渲染。
-
AppleBot 通过基于浏览器的爬网程序呈现 JavaScript,类似于 Googlebot。它处理 JavaScript、CSS、Ajax 请求和整页呈现所需的其他资源。
-
Common Crawl (CCBot) 通常用作大型语言模型 (LLM) 的训练数据集,它不会呈现页面。
数据表明,虽然 ChatGPT 和 Claude 爬虫确实会获取 JavaScript 文件(ChatGPT:11.50%,Claude:23.84% 的请求),但它们不会执行它们。他们无法读取客户端呈现的内容。
但请注意,初始 HTML 响应中包含的内容(如 JSON 数据或延迟的 React 服务器组件)可能仍会被索引,因为 AI 模型可以解释非 HTML 内容。
相比之下,Gemini 对 Google 基础架构的使用使其具有我们在 Googlebot 分析中记录的相同渲染功能,使其能够完全处理现代 Web 应用程序。
内容类型优先级
AI 爬虫在他们获取的内容类型方面显示出不同的偏好。最值得注意的模式:nextjs.org
-
ChatGPT 优先考虑 HTML 内容(占 57.70% 的获取)
-
Claude 非常关注图片(占总抓取量的 35.17%)
-
尽管没有执行 JavaScript 文件,但两个爬虫都在 JavaScript 文件上花费了大量时间(ChatGPT:11.50%,Claude:23.84%)
相比之下,Googlebot 的抓取(跨 Gemini 和 Google 搜索)分布得更均匀:
-
31.00% HTML 内容
-
29.34% JSON 数据
-
20.77% 纯文本
-
15.25% JavaScript
这些模式表明,AI 爬虫收集各种内容类型(HTML、图像,甚至文本形式的 JavaScript 文件),可能会在各种形式的 Web 内容上训练他们的模型。
虽然像 Google 这样的传统搜索引擎已经专门针对搜索索引优化了他们的抓取模式,但较新的 AI 公司可能仍在完善他们的内容优先级策略。
爬行(in)效率
我们的数据显示 AI 爬虫行为效率明显低下:
-
ChatGPT 将其 34.82% 的获取花费在 404 个页面上
-
Claude 表现出类似的模式,34.16% 的获取达到 404 秒
-
ChatGPT 在重定向后额外花费了 14.36% 的获取
对 404 错误的分析表明,除 外,这些爬网程序经常尝试从文件夹中获取过时的资产。这表明需要改进 URL 选择和处理策略,以避免不必要的请求。robots.txt/static/
这些高 404 和重定向率与 Googlebot 形成鲜明对比,后者仅将 8.22% 的抓取用于 404,将 1.49% 的抓取用于重定向,这表明 Google 花费了更多时间优化其爬虫以定位实际资源。
流量相关性分析
我们对流量模式的分析揭示了爬虫行为和网站流量之间有趣的相关性。数据来源:nextjs.org
-
自然流量较高的页面会收到更频繁的爬虫访问
-
AI 爬虫在其 URL 选择中显示不太可预测的模式
-
高 404 率表明 AI 爬虫可能需要改进他们的 URL 选择和验证流程,尽管确切原因尚不清楚
虽然传统搜索引擎已经开发了复杂的优先级算法,但 AI 爬虫似乎仍在发展其 Web 内容发现方法。
建议
对于希望被抓取的网站所有者
-
优先考虑关键内容的服务器端渲染。ChatGPT 和 Claude 不执行 JavaScript,因此任何重要内容都应该由服务器呈现。这包括主要内容(文章、产品信息、文档)、元信息(标题、描述、类别)和导航结构。SSR、ISR 和 SSG 使所有爬虫都能访问您的内容。
-
客户端渲染仍适用于增强功能。您可以随意对非必要的动态元素(如视图计数器、交互式 UI 增强功能、实时聊天小部件和社交媒体源)使用客户端渲染。
-
高效的 URL 管理比以往任何时候都更加重要。AI 爬虫的高 404 率凸显了保持正确重定向、使站点地图保持最新以及在整个站点中使用一致的 URL 模式的重要性。
对于不想被抓取的网站所有者
-
使用
robots.txt控制爬网程序访问。该文件对所有测量的爬网程序都有效。通过指定 AI 爬虫的用户代理或产品令牌来限制对敏感或非必要内容的访问,从而为 AI 爬虫设置特定规则。要找到要禁止的用户代理,您需要查看每家公司自己的文档(例如,Applebot 和 OpenAI 的爬虫)。robots.txt -
使用 Vercel 的 WAF 阻止 AI 爬虫。我们的阻止 AI 机器人防火墙规则允许您一键阻止 AI 爬虫。此规则会自动配置您的防火墙以拒绝其访问。
对于 AI 用户
-
JavaScript 呈现的内容可能缺失。由于 ChatGPT 和 Claude 不执行 JavaScript,因此他们对动态 Web 应用程序的响应可能不完整或过时。
-
考虑一下来源。高 404 率 (>34%) 意味着当 AI 工具引用特定网页时,这些 URL 很可能不正确或无法访问。对于关键信息,请始终直接验证来源,而不是依赖 AI 提供的链接。
-
预计新鲜度不一致。虽然 Gemini 利用 Google 的基础设施进行抓取,但其他 AI 助手的模式则不太可预测。有些可能会引用较旧的缓存数据。
有趣的是,即使向 Claude 或 ChatGPT 请求新的 Next.js 文档数据,我们通常也不会在服务器日志中看到 的即时获取。这表明 AI 模型可能依赖于缓存的数据或训练数据,即使它们声称已获取最新信息。nextjs.org
最后
我们的分析表明,AI 爬虫已迅速成为网络上的重要存在,Vercel 的网络每月有近 10 亿个请求。
但是,在渲染功能、内容优先级和效率方面,它们的行为与传统搜索引擎明显不同。遵循既定的 Web 开发最佳实践(尤其是围绕内容可访问性的最佳实践)仍然至关重要。



发表评论 取消回复