出处:https://careersatdoordash.com/blog/how-to-investigate-the-online-vs-offline-performance-for-dnn-models

机器学习行业中,离线评估与在线推理之间的预测模型性能差异是一个常见且持久的问题,往往限制了模型发挥其全部业务潜力。在DoorDash,这一问题对深度学习模型尤为关键,因为它影响了跨领域的多个团队。缩小这一差距对于最大化模型的商业价值至关重要。
广告质量机器学习团队在最新几版排序模型迭代中也遇到了同样的挑战。本文将以最新发布的模型迭代为案例,逐步展示调试过程,并分享一套可扩展的方法框架,用于调查和解决此类差异。
通过采用本文提出的解决方案,我们将在线-离线AUC差距从4.3%降至0.76%。
我们的经验凸显了关键领域,如特征服务一致性、特征新鲜度,以及集成实时特征进行模型服务时的潜在问题。这些洞见可为未来优化离线与在线性能对齐提供指导。
模型开发背景
"餐厅发现广告"是应用中广告的主要入口,贡献了最大的广告收入。图1总结了自2023年初以来的关键里程碑。在评估多种模型架构后,我们选择了多任务多标签(MTML)模型架构。
图1:餐厅发现广告排序深度学习里程碑
当前里程碑(M4)的目标是通过添加更多特征进一步提升模型性能。在此次迭代中,除了现有特征外,我们新增了40多个稠密特征。
| 特征类别 | 特征类型 | 描述 |
|---|---|---|
| 现有特征 | 稠密特征 | 主要为用户互动特征(如点击、浏览等) |
| 序列特征 | 用户交互的业务/食品/菜系标签序列及上下文特征 | |
| 新增特征 | 稠密特征 | 用户促销相关特征、新增用户互动特征 |
表1:调查模型的特征详情
问题识别
我们基于广泛接受的离线训练数据构建规则开发模型,其中曝光数据与前一天的特征值关联。这种方法模拟了利用“昨日”特征值进行“今日”模型推理的场景。
然而,我们发现实时在线推理的AUC比离线评估下降了4%,且在线AUC显著低于当前生产模型的基线值。
根因分析的思考过程
基于假设驱动的方法
我们通过设计实验验证或推翻每个假设。初始假设包括:
-
特征生成差异:离线特征流水线未模拟在线环境,导致实时预测偏差。
-
数据分布偏移(概念漂移):底层数据分布随时间变化(如用户行为的季节性波动)影响模型泛化。
-
模型服务不稳定:服务基础设施问题(如延迟、模型版本错误)影响在线性能。
针对每个假设,我们进行实验、分析数据、定位根因、应用修复并重新部署模型,直至性能差距解决或新问题出现。
实验设计——离线重放
为了验证特征差异,我们使用相同的在线曝光流量(来自影子模式)重新生成评估数据集,并运行模型推理以评估AUC:
-
若重放AUC与先前离线评估接近,表明性能下降由特征差异导致。
-
若重放AUC与影子模式一致但仍低于离线AUC,则表明存在概念漂移。
关键结果——AUC基准
| 评估日期范围 | 模型 | 特征生成方式 | 在线/离线 | AUC变化 |
|---|---|---|---|---|
| 9月某周数据 | 基线(生产模型) | 在线日志记录 | 在线 | 基线值 |
| 新模型 | 在线日志记录 | 影子模式 | -1.80% | |
| 新模型 | 离线关联新增特征(-1d) | 离线重放 | +2.05% | |
| 6月某周数据 | 基线(生产模型) | 在线日志记录 | 离线 | +0.77% |
| 新模型 | 离线关联新增特征(-1d) | 离线 | +2.105% |
表2:离线重放的AUC基准
模型首次离线训练时,评估集的AUC比基线高2.1%;但在9月影子模式下,AUC下降了1.8%。通过离线重放,AUC提升2.05%,接近原始离线值。这表明特征差异是主要问题。
特征差异调查
特征陈旧性 vs 缓存残留
-
特征陈旧性:特征值因流水线延迟(如-1d/-2d)未及时更新。
-
缓存残留:旧特征值未被清除,导致在线服务使用过时数据。
关键洞见
-
特征陈旧性:离线使用的-1d特征偏移过于激进,实际在线特征值多来自用户2-3天前的行为。
-
缓存残留:超过4天的特征值可能残留在特征库中,降低在线服务的缺失率,加剧差异。
表3:新增重要特征的缓存残留分析
验证假设与闭环
通过重建不同特征偏移(-1d至-4d)的数据集并训练模型,我们发现:
-
特征新鲜度下降导致AUC显著降低(图4)。
-
从-1d到-2d的延迟对性能影响最大。
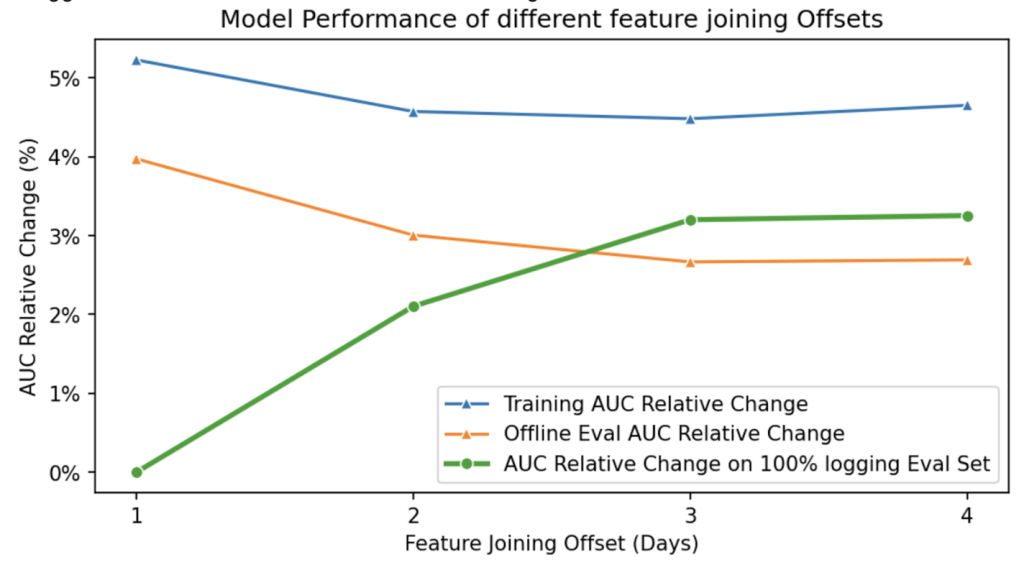
图4:不同特征偏移训练的模型AUC相对变化
解决方案
| 方案 | 优点 | 缺点 |
|---|---|---|
| 短期 | 立即减少AUC差异 | 无法解决缓存残留问题 |
| 长期 | 解决缓存残留和特征陈旧性 | 需权衡开发速度与数据准确性 |
表5:短期与长期方案对比
实验结果与结论
采用短期方案后,在线-离线AUC差距从4.3%降至0.76%。结合其他特征改进,此次迭代成为今年广告排序模型中业务收益最大的一次。
本次调查不仅解决了性能差距,还揭示了实时系统中特征对齐的重要性。该方法论可为其他领域提供参考。未来,通过强化日志系统和扩展特征流水线,我们将持续推动模型业务价值。
延伸思考
为何2023年前在线-离线差距不明显?
-
业务规模:广告业务过去一年增长3-5倍,数据量与特征复杂度放大特征问题。
-
模型架构:树模型对特征差异不敏感(通过分箱处理),而DNN作为参数模型对特征值精度高度敏感。
发表评论 取消回复